



.svg)



In a live phone conversation, every second matters. A delay of even a few hundred milliseconds can disrupt the natural rhythm of dialogue.
At the same time, allowing an LLM to make high-stakes decisions without sufficient oversight introduces real risk: hallucinations, policy violations, or incorrect actions that impact customers.
This creates a fundamental tension. The most reliable LLM behaviors typically come from larger models with higher token budgets, but also come at the cost of speed. In real-time voice applications, we can’t simply default to the biggest and most thorough model at every step.
So how do we balance reliability with latency?
At Replicant, we approach this as a systems design problem. We design guardrails that operate at different speeds, running at different points in the lifecycle of a conversation. Some checks operate under sub-second constraints, while some run longer; the longest-running checks will even take place after a conversation has ended.
By strategically distributing supervisory LLMs across real-time and offline contexts, we’re able to combine fast responses with deeper validation—without sacrificing the natural flow of conversation. The result is a multi-tiered approach that optimizes for both responsiveness and reliability, acknowledging that no single model configuration can perfectly satisfy both constraints simultaneously.
Let’s explore how these tradeoffs play out in practice, and how layering different types of supervision allows us to deliver production-grade performance in real-world voice environments.
Balancing the tradeoffs of supervisor LLMs
When operating under real-world constraints, we need to make thoughtful trade-offs. Even using a reasoning LLM (which is increasingly the default expectation in most AI use cases) may be prohibitively slow when having a real-time conversation over the phone.
But using larger models with higher reasoning token budgets is the clearest path to getting more reliable LLM behavior. So how do we balance reliability with real-time constraints?
We take advantage of these more powerful models when we can, and prioritize conversation speed wherever possible:
1. Real-time, online
To respond to the caller over the phone in real time, latency is absolutely critical. Our guardrails that run simultaneously with a live conversation need to use parallelization, faster models, and minimal reasoning steps to maintain the low latency expected in natural conversation.
- LLM reasoning is a tunable knob. Reasoning LLMs offer out-of-the-box level parameters, but non-reasoning LLMs are still capable of performing reasoning based on how they are prompted to “think” before responding.
- When guarding against many failure modes, it is almost always preferable from a latency perspective to use a team of supervisors, each focused on identifying issues within a narrow problem space, rather than coaxing a single LLM into quickly (and accurately!) ruling out all possible errors.
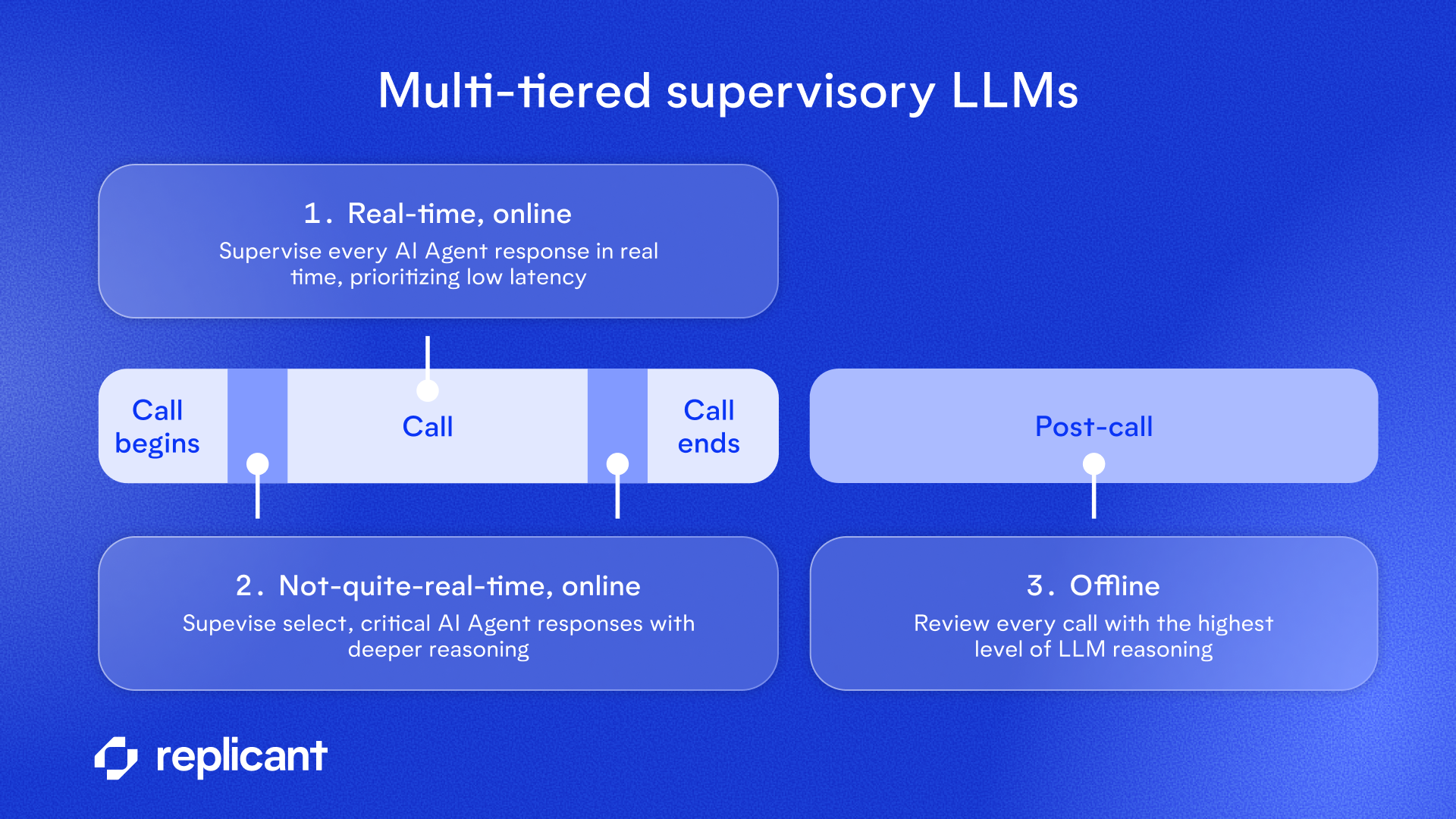
2. Not-quite-real-time, online
While it’s not advantageous to have long delays for the caller at every point in the call, it is generally acceptable to introduce delays if they are infrequent and properly communicated.
- For example, early in the call, when we are taking an important step such as authenticating a caller, we may ask them to hold briefly while we spend additional processing time analyzing the information provided.
- Similarly, at the end of a call, before concluding with the caller, we may ask them to hold briefly while we review all of the interactions in the call history for hallucinations.
3. Offline
Even after a call is finished, it is still valuable to surface a hallucination. Offline supervisory LLMs have the luxury of using the most computationally expensive strategies at this point, because there is no caller on the other end waiting for our response. We use higher reasoning supervisor LLMs for every conversation for several reasons:
- In the rare case an issue is identified, we can notify our customer and explore the possibility of remediating the isolated incident.
- We can make adjustments to the agent so that it avoids the same mistake in the future.
- We can use learnings from every supervisory LLM to inform conversation design and strengthen best practices across all AI Agents.
Multi-tiered approach
Supervisory LLMs are but one of many guardrail strategies that we use at Replicant. In fact, combining several guardrail concepts is the best way to achieve extremely high reliability while operating under other enterprise constraints. You can learn more about our multi-tiered strategy with these write-ups on our approach to guardrails, deterministic execution, and security testing.
Schedule time with an expert to learn more about how Replicant can transform your contact center with AI.
